




 PDF
PDFОдин из доступных алгоритмов соединения двух таблиц в SQL Server это вложенные циклы (Nested Loops). В зависимости от выбранного оптимизатором порядка соединения таблиц, одна из таблиц выбирается как внешняя (по ней открывается внешний цикл), вторая как внутренняя (для каждой строки из внешней таблицы выполняется внутренний цикл по второй таблице), во время соединения, внутри циклов проверяется условие соединение, такой подход называется «наивный» алгоритм вложенных циклов. Если же по внутренней таблице доступен индекс по условию соединения, то необязательно выполнять внутренний цикл проверки по каждой строке второй таблицы, вместо этого, можно передать в качестве аргумента поиска значение из внешней таблицы, а все строки, что будут найдены во внутренней таблице соединить со строкой из внешней таблицы.
Поиск по внутренней таблице — это случайный доступ, SQL Server начиная с версии 2005 имеет оптимизацию, называемую batch sort (не путать с оператором Sort в Batch Mode для колоночных индексов). Идея оптимизации заключается в том, чтобы перед тем, как получить данные из внутренней таблицы, упорядочить ключи поиска из внешней, превратив тем самым случайный доступ в последовательный.
Операция batch sort не видна в плане запроса, как отдельный оператор, вместо этого, вы можете наблюдать в операторе Nested Loops свойство Optimized=true. Если бы можно было увидеть batch sort как отдельный оператор в плане, это бы выглядело примерно следующим образом:

В данном «псевдо-плане», мы читаем данные из некластерного индекса ix_CustomerID в порядке ключа этого индекса CustomerID, после чего, нам необходимо выполнить Key Lookup в кластерный индекс (т.к. индекс ix_CustomerID не является покрывающим для запроса, по которому получен данный «псевдо-план»). Key Lookup – это операция поиска по ключу кластерного индекса, случайный доступ, и чтобы превратить его в последовательный сервер может выполнить batch sort по ключу кластерного индекса.
Подробнее по batch sort вы можете почитать в моем англоязычном блоге, в статье Batch Sort and Nested Loops.
Эта оптимизация дает хорошее ускорение при достаточном числе строк, вы можете ознакомиться с результатами тестирования эффекта этой оптимизации в блоге одного из разработчиков оптимизатора Крейга Фридмана OPTIMIZED Nested Loops Joins.
Однако, если строк меньше, чем ожидалось, то дополнительные затраты CPU на построение этой сортировки могут скрадывать ее выгоды, увеличивать потребление процессора и замедлять выполнение. До появления подсказки DISABLE_OPTIMIZED_NESTED_LOOP Microsoft предлагала в таком случае воспользоваться флагом трассировки 2340, он отключает эту оптимизацию. Теперь, в этом нет необходимости и мы можем использовать хинт DISABLE_OPTIMIZED_NESTED_LOOP.
Пример
Рассмотрим пример:
use tempdb;
go
-- Создадим тестовую таблицу (SalesOrderID - кластерный ПК)
create table dbo.SalesOrder(SalesOrderID int identity primary key, CustomerID int not null, SomeData char(200) not null);
go
-- Заполним ее тестовыми данными
with n as (select top(1000000) rn = row_number() over(order by (select null)) from sys.all_columns c1,sys.all_columns c2)
insert dbo.SalesOrder(CustomerID, SomeData) select rn%500000, str(rn,100) from n;
-- Создадим некластерный индекс
create index ix_c on dbo.Salesorder(CustomerID);
go
-- По умолчанию оптимизация batch sort включена (Nested Loops: Optimized = true)
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000;
-- Отключаем ее хинтом DISABLE_OPTIMIZED_NESTED_LOOP (Nested Loops: Optimized = false)
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000 option(use hint('DISABLE_OPTIMIZED_NESTED_LOOP'));
go
Результат:
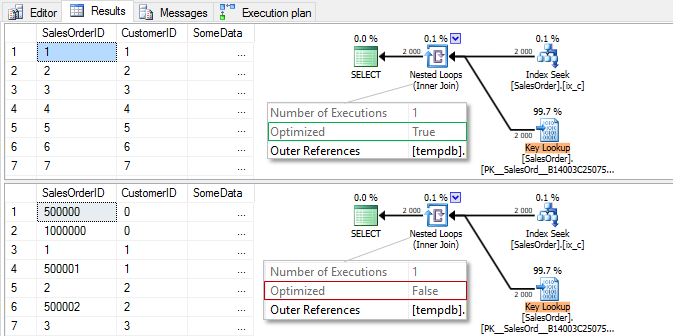
Обратите внимание на разный порядок строк при выводе, т.к. у нас не задан явный порядок при помощи ORDER BY, сервер возвращает строки в порядке их обработки. В первом случае, мы последовательно читаем из индекса ix_c, но для оптимизации случайных чтений из кластерного индекса, сортируем по ключу кластерного индекса SalesOrderID. Во втором случае, сортировка не происходит и чтения идут в порядке ключей CustomerID в некластерном индексе ix_c.
Отличие от флага 2340
Несмотря на то, что в документации флаг 2340 указан как эквивалент хинта DISABLE_OPTIMIZED_NESTED_LOOP, это не совсем так.

Рассмотрим следующий пример, в котором при помощи недокументированной команды UPDATE STATISTICS … WITH PAGECOUNT, я обману оптимизатор, сказав, что таблица занимает больше страниц, чем на самом деле. Не принципиально использовать именно эту команду, можно было просто сделать таблицу шире, но я хочу сэкономить время. После этого, посмотрим на три запроса:
- без любых подсказок (MAXDOP, добавлено для сохранения простой формы плана);
- с хинтом DISABLE_OPTIMIZED_NESTED_LOOP;
- с флагом трассировки 2340.
-- Имитируем широкую таблицу
update statistics dbo.SalesOrder with pagecount = 100000;
go
set showplan_xml on;
go
-- 1. Без подсказок
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000000 option(maxdop 1);
-- 2. Хинт
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000000 option(use hint('DISABLE_OPTIMIZED_NESTED_LOOP'), maxdop 1);
-- 3. Флаг трассировки
select * from dbo.SalesOrder with(index(ix_c)) where CustomerID < 1000000 option(querytraceon 2340, maxdop 1);
go
set showplan_xml off;
go
В результате мы получим следующие планы:

Во всех трех планах, Nested Loops имеет свойство Optimized = false. Дело в том, что, увеличив ширину таблицы, мы увеличили стоимость доступа к данным. При достаточно высокой стоимости, сервер может решить вместо неявной batch sort, использовать явный оператор сортировки Sort, что он и делает в данном случае. Мы наблюдаем это в плане первого запроса.
Во втором запросе, мы использовали хинт DISABLE_OPTIMIZED_NESTED_LOOP, который отключает неявный batch sort, но он также убирает и явную сортировку отдельным оператором. В третьем плане, мы видим, что несмотря на добавление флага 2340, оператор сортировки присутствует.
Таким образом, хинт отличается от флага тем, что отключает оптимизацию по преобразованию случайного доступа в последовательный полностью, вне зависимости от того, как сервер решит ее реализовать, с помощью неявной сортировки batch sort или с помощью отдельного оператора Sort.
В следующей заметке мы поговорим про хинты FORCE_LEGACY_CARDINALITY_ESTIMATION и FORCE_DEFAULT_CARDINALITY_ESTIMATION.
P.S. Планы в этой заметке могут зависеть от оборудования, так, если у вас не получается воспроизвести примеры, попробуйте увеличить или уменьшить размер столбца SomeData char(200) в определении таблицы dbo.SalesOrder.





Только у меня вопрос повис, чем отличаются пакетная сортировка от старорежимной?
Спасибо за вопрос.
Отличается режимом выполнения. Одна получает на вход строки, другая пакеты строк.
В смысле плана выполнения это значит, что если сортировка в пакетном режиме не поддерживается, то сервер вынужден конвертировать пакеты в строки (при помощи скрытого из плана оператора Adapter), что требует дополнительных ресурсов и плохо сказывается на производительности. На самом низком уровне это означает, что хотя вы видите в плане запроса оператор с одним и тем же названием, отличающемся только свойствами, реально внутри сиквела это выполняется разными операторами, разными ветками кода. Эффективность в режиме Batch тем выше, чем больше число обрабатываемых оператором строк.
Если говорить про какие-то частные вещи, то сортировка в режиме batch работает по другому с памятью, а также, умеет запрашивать дополнительную память. Можете почитать мою статью SQL Server 2017: Sort, Spill, Memory and Adaptive Memory Grant Feedback, где есть некоторые подробности на эту тему.