




 PDF
PDFВ этой публикации я хочу поговорить о новых методах обработки запросов, которые призваны бороться с ошибками в оценках кардинальности, предполагаемом числе строк в операторах плана запроса, и улучшать производительность. Эти методы объединяются под общим названием – Adaptive Query Processing, и состоят из трех основных компонентов:
- Adaptive Memory Grant Feedback
- Interleaved Execution
- Adaptive Joins
Далее мы рассмотрим каждый из этих методов, где они применяются и какой имеют эффект. Для демонстрации примеров я буду использовать SQL Server 2017 CTP 2.0 совместно с SQL Server Management Studio 17.0.
Adaptive Memory Grant Feedback
В SQL Server существуют операторы плана, например, такие как Hash Match или Sort, которые требуют память во время выполнения запроса. В частности, оператор Sort требует память для создания внутренних структур данных, в которых будут храниться промежуточные отсортированные результаты.
Размер этой памяти, так называемый грант памяти, вычисляется в момент компиляции запроса на основании предполагаемого числа строк и размера строки, в дальнейшем, при выполнении запроса, он не меняется. Таким образом, если при компиляции размер был вычислен неверно, например, из-за ошибочной оценки предполагаемого числа строк, в момент выполнения, памяти может не хватить.
SQL Server спроектирован таким образом, что если, выделенной на основе предварительных расчетов, памяти не хватает, он не может запрашивать дополнительную память динамически и вынужден сливать (spill) данные промежуточных результатов в базу tempdb. Бывают исключения, когда дополнительная память может быть запрошена, например, если оператор сортировки используется при построении индекса или, в новых версиях SQL Server, в режиме Batch, включены динамические гранты памяти. В большинстве же случаев дополнительная память не запрашивается и сервер вынужден работать с tempdb.
Использование tempdb вместо оперативной памяти обычно сильно замедляет работу запроса, и чем больше ошибка в гранте памяти, тем больше данных будет слито в tempdb, и тем медленнее будет работать запрос. В новых версиях сиквела в такой ситуации в действительном плане запроса выдается предупреждение «Operator used TempDB to spill data during execution», а над иконкой проблемного оператора возникает желтый треугольник с восклицательным знаком.
Adaptive Memory Grant Feedback, дословно, адаптивный грант памяти, призван бороться с такой ситуацией и менять грант памяти от выполнения к выполнению, в зависимости от реального числа обработанных строк. К сожалению, если ошибка вызвана неверно вычисленным размером строки, Adaptive Memory Grant Feedback не будет работать, по крайней мере в текущей версии.
Есть несколько условий, которые должны быть соблюдены, чтобы SQL Server смог использовать этот механизм. На момент текущей версии это:
- БД должна иметь уровень совместимости 140;
- план должен находиться в кэше и быть использован повторно;
- запрос должен выполняться в режиме Batch (Microsoft не исключает возможности в будущем расширить это и на традиционный режим Row, но в текущей версии поддерживается только режим Batch).
Давайте посмотрим, как это работает на примере. Я использую БД AdventureworksDW2016CTP3 и чтобы имитировать ошибку кардинальности, но при этом сохранить максимально простую форму плана – я обновлю статистику таблицы при помощи недокументированной опции rowcount. С ее помощью мы скажем серверу о том, что в таблице 5 000 000 строк, тогда как в реальности там 11 669 600 строк, т.е. примерно в два раза больше. Затем мы выполним запрос с сортировкой три раза и посмотрим на гранты памяти в плане. Также я включу несколько расширенных событий, чтобы увидеть, что произошло во время выполнения запросов.
alter database AdventureworksDW2016CTP3 set compatibility_level = 140;
go
update statistics dbo.FactResellerSalesXL_CCI with rowcount = 5000000 --11669600
alter database scoped configuration clear procedure_cache;
go
select
CarrierTrackingNumber
from
dbo.FactResellerSalesXL_CCI c
where
c.DueDate between '20140101' and '20150101'
order by
c.CarrierTrackingNumber, c.CustomerPONumber
;
go 3
Давайте взглянем на планы:
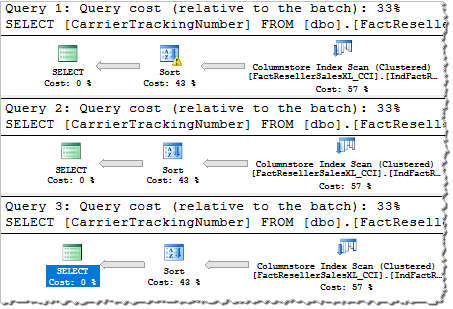
Мы видим, что при первом выполнении над оператором сортировки изображен треугольник с восклицательным знаком, что говорит о том, что при первом выполнении этот оператор сливал данные в tempdb. Если мы посмотрим на свойства этого оператора, то мы увидим предупреждение: «Operator used tempdb to spill data during execution with spill level 8 and 1 spilled thread(s)».
При втором и третьем выполнении мы видим, что никакого слива данных нет и сортировка выполнялась в памяти. Давайте посмотрим на гранты памяти.

Мы видим, что при первом выполнении свойство Desired Memory (память, требуемая для выполнения запроса), равно примерно 66 МБ, хотя реально было использовано около 86 МБ (немного больше чем 66 МБ, т.к. сортировка в режиме Batch выделяет память иначе, чем сортировка в режиме Row, более подробно описывал это в статье SQL Server 2017: Sort, Spill, Memory and Adaptive Memory Grant Feedback) и этой памяти не хватило, поэтому данные были слиты в tempdb.
При втором выполнении, свойство Desired Memory было увеличено до 211 МБ, а реально было использовано около 94 МБ. Слива данных не произошло, памяти хватило, но 211 МБ это больше чем нужно, то есть происходит перерасход памяти.
В третьем выполнении грант памяти был уменьшен до 124 МБ и на этот раз он ближе к действительно используемому значению, таким образом слива данных не происходит и в то же время нет большого перерасхода памяти.
Если мы посмотрим на сессию расширенных событий, то мы там увидим три события.

Первое событие говорит о том, что произошел слив данных в tempdb и указывает размер слитых данных. Второе говорит о том, что был применен adaptive memory grant feedback и грант дополнительной памяти (ideal_additional_memory_before_kb) был увеличен с 66 МБ до 211 МБ (ideal_additional_memory_after_kb). Третье событие говорит о том, что грант был уменьшен, чтобы не перерасходовать память, но ее осталось достаточно, чтобы избежать работы с tempdb.
Если вы по какой-то причине хотите отключить этот механизм, то документированный способ — это вернуться на предыдущий уровень совместимости. Однако, я поделюсь еще одним способом, не документированным на данный момент, хотя очень надеюсь, что он будет документирован.
Это подсказка (hint) DISABLE_BATCH_MODE_MEMORY_GRANT_FEEDBACK.
Вы можете использовать ее следующим образом:
select
CarrierTrackingNumber
from
dbo.FactResellerSalesXL_CCI c
where
c.DueDate between '20140101' and '20150101'
order by
c.CarrierTrackingNumber, c.CustomerPONumber
option(use hint('DISABLE_BATCH_MODE_MEMORY_GRANT_FEEDBACK'))
При этом, грант памяти не будет меняться, и вы получите Spill во всех трех выполнениях:

Это ключевое слово также доступно в качестве настройки уровня базы данных, если вы хотите отключить этот механизм для всей БД:
alter database scoped configuration set DISABLE_BATCH_MODE_MEMORY_GRANT_FEEDBACK = on|off;
Пожалуйста, помните, что это не документировано (во всяком случае пока) и предназначено только для экспериментов.
Мы посмотрели, как работает Adaptive Memory Grant Feedback и что он позволяет делать. Очень надеюсь, что эта технология будет расширена на традиционный режим обработки Row и это войдет в финальный релиз SQL Server 2017.
Следующим пунктом мы рассмотрим другой метод адаптивной обработки, который называется Interleaved Execution.
Interleaved Execution
Функции в программировании — это удобный инструмент для повышения качества кода, создания модульности, переиспользуемости и т.д. Однако, в мире SQL Server использование функций тесно связано с проблемами производительности.
Существует три типа пользовательских TSQL функций: табличная Inline, скалярная функция и табличная Multistatement.
Inline функции, которые также называют параметризованными представлениями, хорошо взаимодействуют с оптимизатором, поскольку их код встраивается в тело оптимизируемого запроса (отсюда и inline) и запрос оптимизируется целиком. Это значит, что оптимизатор имеет представление о кардинальности таблиц, о статистике, запросе и других важных для оптимизации вещах. Однако, слабость этого вида функций в том, что в них нельзя использовать управляющие (flow control) операторы, например, IF или WHILE, а также объявлять переменные, создавать временные таблицы и многое другое.
Скалярные функции и их производительность заслуживают отдельной темы, но мы не будем их обсуждать в этой публикации, поскольку они не связаны с темой этой статьи. Вместо этого, мы остановимся на последнем виде функций – Transact-SQL Multistatement Table-valued Functions (MTVF).
MTVF функции позволяют использовать разные элементы языка и являются более сильным инструментом чем Inline функции. К сожалению, вместе с тем, они являются для оптимизатора черным ящиком, с точки зрения статистических данных. Число строк, возвращаемое табличной функцией, является фиксированной оценкой и не зависит от того, сколько строк функция возвращает на самом деле. До 2014 сервера оценка была 1 строка, в 2014 и 2016 эта оценка увеличилась до 100 строк, но также осталась фиксированной (более подробно эта тема изложена в моей статье MTVF and CE Model Variation).
SQL Server 2017 при определённых условиях может использовать действительное число строк возвращенное функцией и оптимизировать остальную часть плана с учетом действительного числа строк, возвращенного функцией. Это стало доступно благодаря технологии Interleaved Execution, дословно, чередующееся выполнение.
При оптимизации запроса с возможностью Interleaved Execution, оптимизатор не строит план целиком. Вместо этого он создает некоторую «заглушку» плана, затем выполняет функцию, берет реальное число строк после её выполнения и оптимизирует план запроса с учетом этого числа строк.
Есть несколько основных условий, чтобы сервер мог применить Interleaved Execution, во первых, уровень совместимости БД должен быть равен 140, во вторых функция не должна получать на вход коррелированные параметры из внешнего запроса.
Давайте посмотрим, как это работает на примере. Я использую все ту же базу данных AdventureworksDW2016CTP3.
Создадим в ней простую MTVF функцию и выполним запрос с этой функцией под уровнями совместимости 130 и 140. После этого посмотрим на разницу в планах выполнения.
-- Create multistatement table-valued function
create or alter function dbo.uf(@n int)
returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint)
with schemabinding
as
begin
insert @t(SalesOrderNumber, SalesOrderLineNumber)
select top(@n)
SalesOrderNumber,
SalesOrderLineNumber
from
dbo.FactResellerSalesXL_CCI;
return;
end
go
-- Clear procedure cache for DB
alter database scoped configuration clear procedure_cache;
-- Set compatibility level of SQL Server 2016
alter database AdventureworksDW2016CTP3 set compatibility_level = 130;
go
-- Run the query with mTVF
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber;
go
-- Clear procedure cache for DB
alter database scoped configuration clear procedure_cache;
-- Set compatibility level of SQL Server 2017
alter database AdventureworksDW2016CTP3 set compatibility_level = 140;
go
-- Run the query with mTVF
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber;
go
План запроса для уровня совместимости с 2016 сервером:

Мы видим оценку в 100 строк, тогда как реально их было 10 000. Такая оценка повлекла за собой выбор алгоритма Nested Loops Join, Stream Aggregate и поиск по некластерному индексу.
Теперь, давайте посмотрим на план с уровнем совместимости 2017 сервера:

Мы видим совершенно другой план. Во-первых, обратите внимание на оценку числа строк в функции, Estimated Number Of Rows, она равна 10 000, что полностью совпадает с действительным числом строк.
Во-вторых, эта оценка и число строк показались серверу достаточными для того, чтобы применить частичную (partial) агрегацию, поэтому, кроме Stream Aggregate мы видим еще и Hash Match Aggregate до соединения.
В-третьих, обратите внимание на оператор соединения – Adaptive Join (речь о нем пойдет ниже в статье). Во время выполнения этот оператор использовал тип физического соединения Hash Match. Из-за выбранного типа на внутреннем входе соединения уже не поиск по некластерному индексу, а сканирование колоночного индекса с фильтрацией.
Если мы включим Profiler и добавим туда события SP:StmtStarting, SP:StmtCompleted, SQL:StmtStarting и SQL:StmtCompleted, то мы увидим, как запрос выполняется в обычном порядке, а как в случае Interleaved Execution.


Вы видите, что в первом случае, запрос начинает выполняться, потом выполняется функция, и потом запрос завершается. Во втором случае, сначала выполняется функция, а уже потом выполняется сам запрос.
Для отключения этого механизма, так же, как и в предыдущей части единственный пока, документированный, способ — это использовать предыдущий уровень совместимости БД. Однако, как и в предыдущей части, я поделюсь недокументированной подсказкой. Это подсказка DISABLE_INTERLEAVED_EXECUTION_TVF. Использовать ее можно следующим образом:
-- Clear procedure cache for DB
alter database scoped configuration clear procedure_cache;
-- Set compatibility level of SQL Server 2017
alter database AdventureworksDW2016CTP3 set compatibility_level = 140;
go
set statistics time on;
-- Run the query with mTVF
select
c = count_big(*)
from
dbo.FactResellerSalesXL_CCI c
join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber
option(use hint('DISABLE_INTERLEAVED_EXECUTION_TVF'));
set statistics time off;
go
При этом, план запроса сохраняет нововведения 2017 сервера, например, Adaptive Join, но мы уже не видим частичной агрегации Hash Match Aggregate, поскольку оценочное число строк равно 100.

При помощи этого же ключевого слова есть возможность отключить данный механизм на уровне БД следующим образом:
alter database scoped configuration set DISABLE_INTERLEAVED_EXECUTION_TVF = on|off;
Еще раз напоминаю, что это недокументированная (на момент написания публикации) команда и ее нужно использовать в тестовых и экспериментальных целях.
Более подробно я разобрал механизм Interleaved Execution в своей публикации SQL Server vNext: Interleaved Execution for mTVF, а мы перейдем к завершающему элементу из семейства Adaptive Query Processing – Adaptive Join.
Adaptive Join
SQL Server имеет три физических типа соединений Nested Loops Join, Hash Join и Merge Join. Каждый из них хорош при определенных условиях.
Так, если соединяется небольшое число строк с большим числом строк, и в таблице с большим числом строк есть индекс по колонке соединения, то Nested Loops Join показывает хорошие результаты. Выполняется так называемый index nested loops join или nested loops apply. Более подробно я описывал стратегию и виды соединения Nested Loops в статье USE HINT и DISABLE_OPTIMIZED_NESTED_LOOP. Hash Join хорошо работает если соединяемые наборы строк достаточно большие, при этом индекса по столбцам соединения может и не быть.
Иногда возникает ситуация, когда из-за неверных оценок при построении плана сервер выбирает неоптимальный тип соединения. Наиболее характерный пример, это когда из-за недооценки строк на одном из входов соединения, например, оценка в одну строку, а в реальности их сто — выбирается тип Nested Loops, при этом на втором входе тяжелый оператор сканирования всей таблицы или индекса. Сервер предполагает, что, получив одну строку на первый вход, он выполнит сканирование второго, внутреннего, входа один раз. В реальности он выполняет сканирование сто раз и запрос работает очень медленно.
Adaptive Join позволяет в момент выполнения переключаться с Hash Join на Nested Loops Join в зависимости от того, был ли преодолён некий внутренний порог, который называется Adaptive Threshold Rows и доступен в плане запроса с Adaptive Join. При таком подходе мы можем получить лучшее из двух алгоритмов соединения, так, если строк достаточно мало, используется алгоритм Nested Loops и мы можем избежать сканирования таблицы или индекса на внутреннем входе. В то же время, если строк достаточно много, мы можем избежать множественных операций случайного доступа в виде поиска по индексу или еще лучше, множественных сканирований внутреннего входа, если поиск по индексу невозможен.
Параметр Adaptive Threshold Rows отвечающий за переключение физического алгоритма соединения, вычисляется в момент компиляции на основе оценок и определяет число строк исходя из стоимости, выгоднее ли использовать Nested Loop или Hash.
Перед тем, как мы посмотрим пример, я хочу сказать о важном ограничении в применении этого функционала, а именно, он доступен только под уровнем совместимости 140 и, самое главное, если оптимизатор рассматривает режим выполнения Batch, т.е. на таблице должен быть колоночный индекс.
Хочу сказать спасибо Ицику Бен-Гану, который придумал хороший трюк с фиктивным (dummy) фильтрованным колоночным индексом, который не занимает место, но формально дает оптимизатору право на режим выполнения Batch. Впервые этот трюк был описан в его статье What You Need to Know about the Batch Mode Window Aggregate Operator in SQL Server 2016: Part 1 и теперь распространен на оператор плана Adaptive Join. Рекомендую ознакомиться с оригиналом статьи What You Need to Know about Adaptive Joins over Rowstore, т.к. мы применим такой же трюк в примере ниже.
Давайте перейдем к примеру. Я буду использовать БД AdventureWorks2016CTP3 под уровнем совместимости 140, создам на таблице пустой фильтрованный колоночный индекс, а после этого выполню запрос с соединением и параметром.
use AdventureWorks2016CTP3;
go
alter database [AdventureWorks2016CTP3] set compatibility_level = 140;
go
create nonclustered columnstore index dummy on Sales.SalesOrderHeader(SalesOrderID) where SalesOrderID = -1 and SalesOrderID = -2;
go
declare @TerritoryID int = 1;
select
sum(soh.SubTotal)
from
Sales.SalesOrderHeader soh
join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID
where
soh.TerritoryID = @TerritoryID;
go
Давайте посмотрим на план запроса:
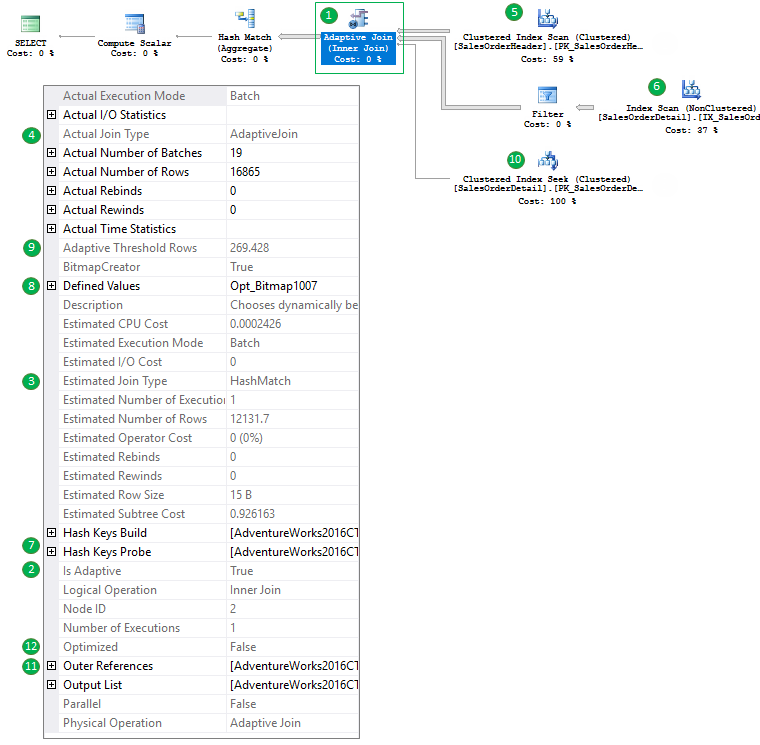
- Вы можете видеть новый оператор Adaptive Join.
- Свойство плана Is Adaptive установлено в TRUE.
- Оценочный тип соединения, на основе оценочного числа строк – Hash Match Join. Если мы, например, добавим в запрос «option (optimize for (@TerritoryID = 0))», а в таблице и статистке нет строк с TerritoryID = 0, то мы увидим оценочный тип соединения Nested Loops.
- Действительный тип соединения Adaptive Join, но как говорят Microsoft это пока является недоработкой и в следующей версии тут будет реальный физический тип соединения, который был использован при выполнении запроса.
- Мы видим Clustered Index Scan таблицы SalesOrderHeader на первом входе соединения – этот вход используется для построения build части Hash Join (7)
- Мы видим Index Scan таблицы SalesOrderDetail в качестве второго входа, для Hash Match это probe часть.
- Мы видим свойства Hash Key Build и Probe, которые обычно являются свойствами оператора Hash Match.
- Мы также видим Bitmap фильтр, который также обычно появляется в типах соединений Hash Join (иногда Merge).
- Затем мы можем наблюдать свойство Adaptive Join Threshold, это число строк, которое используется для переключения физического алгоритма соединения и входящими ветками 6 (для Hash) или 10 (для Nested Loops).
- Это ветка, которая будет использована, если Adaptive Join переключится на алгоритм Nested Loops, т.к. порог (9) не был достигнут. Важно сказать, что при переключении, первый вход не сканируется повторно, используются уже прочитанные данные.
- Обратите внимание на свойство Outer Reference, это свойство Nested Loops Join, которое в нашем случае равно SalesOrderID (колонке соединения).
- Также вы можете заметить свойство Optimized, используемое алгоритмом Nested Loops Join для уменьшения случайного доступа на внутренней стороне соединения. Вы можете посмотреть мою статью, более подробно описывающую это свойство.
Таким образом мы видим, что в зависимости от реального количества строк на первом входе сервер может использовать тот или иной тип соединения. Эта ситуация очень хорошо решает проблему прослушивания параметров, когда нам необходимо либо прочитать много строк, либо очень мало, в зависимости от значения параметра. Однако, сам порог переключения также строится в момент компиляции и если число строк на первом входе тоже зависит от параметра, то к нему проблема прослушивания параметров будет применена в полной мере. Этот пример очень хорошо описан в статье Ицика, приведенной выше, так что рекомендую ознакомиться, если еще не успели.
Если вы по какой-то причине хотите отключить этот функционал, то, как было сказано выше, пока единственным документированным способом является переключение на более низкий уровень совместимости БД. Однако, как и в предыдущих пунктах, я поделюсь с вами недокументированной подсказкой, которую можно использовать в своих экспериментах.
Это подсказка DISABLE_BATCH_MODE_ADAPTIVE_JOINS.
Вы можете использовать ее следующим образом:
alter database scoped configuration clear procedure_cache;
go
declare @TerritoryID int = 1;
select
sum(soh.SubTotal)
from
Sales.SalesOrderHeader soh
join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID
where
soh.TerritoryID = @TerritoryID
option(use hint('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
go
В итоге будет получен следующий план:

Наравне с предыдущими подсказками, это ключевое слово также доступно в качестве настройки уровня БД:
alter database scoped configuration set DISABLE_BATCH_MODE_ADAPTIVE_JOINS = on|off;
При этом призываю помнить, что это пока не документировано.
Более подробно я рассмотрел механизм Adaptive Joins в своей статье SQL Server 2017: Adaptive Join Internals.
Заключение
SQL Server становится «умнее» от версии к версии, и в этой публикации мы рассмотрели некоторые техники обработчика запросов, которые позволяют снизить негативный эффект от ошибок кардинальности в момент построения плана за счет адаптации плана к реальным значениям в момент его выполнения.
Эта статья не ставит себе целью тестирование производительности и эффекта от нововведений, она призвана познакомить вас с новыми возможностями. Вы можете самостоятельно проверить эффективность новых методов на своих данных и поделиться вашими результатами.
Ниже приведен список литературы по этой теме, как мои статьи, с более подробным описанием каждого из механизмов, так и статьи других авторов.
Спасибо за чтение!
Дополнительная литература
- SQL Server 2017: Sort, Spill, Memory and Adaptive Memory Grant Feedback
- SQL Server vNext: Interleaved Execution for mTVF
- SQL Server 2017: Adaptive Join Internals
- Introducing Batch Mode Adaptive Memory Grant Feedback
- Introducing Interleaved Execution for Multi-Statement Table Valued Functions
- Introducing Batch Mode Adaptive Joins
- What You Need to Know about Adaptive Joins over Rowstore





Спасибо, отличная статья! Остался вопрос по Spool’ам и производительности. Получается требования к памяти в данном случае теперь такие же как если бы был Hash Join, даже если будет использован Loop, т.к. таблица в памяти (или в tempdb) будет построена в любом случае. При таком типе соеденения теперь могут появиться Spill даже если используется Loop + проблемы с кешированым планом, как показано в статье Бен Гана. Отсюда вопрос, насколько уместно использовать хинты для запросов где наверника будет использован Loop? Если таких запросов в системе довольно много, доп. расходы на память при Adaptive Join могут быть существенны, а выгода от его использования сомнительна.
Добрый день, Алексей. Отличный вопрос.
Да, требования к памяти возрастут, если вы смотрели статьи от МС ниже по ссылкам, то вы там увидите ответ от Joe Sack:
Что касается хинтов, вопрос хороший, но нужно помнить, что в версии 2017 CTP 2.0, МС официально анонсирует только Batch Mode Adaptive Joins (хоть они и могут выполняться в Row Mode), т.е. это подразумевает наличие Columnstore индекса на таблице. Таблицы, на которых имеет смысл создавать колоночные индексы, как правило, очень большие и преимущественно в таких запросах и так используется Hash Join. То что показал Ицик, это все-таки такой «трюк»/»приём». Если вы не хотите, чтобы на каких-то запросах с Rowstore таблицами использовался такой вид соединения — просто не создавайте там фиктивный колоночный индекс, оптимизатор не будет рассматривать Adaptive Join. Если же у вас большинство запросов с колоночными индексами, но при этом выгоднее Nested Loops и при этом мало памяти — это не очень типичный случай. В таком случае, я бы рекомендовал проводить тщательное тестирование. Хотя, проводить тестирование полезно в любом случае. =)
Технология пока очень новая, посмотрим, каким образом МС реализует поддержку Adaptive Join для Row Store в будущих версиях, ведь такие мысли есть (из той же статьи):
Спасибо за ответ!
Да, вопрос был скорее на будущее, плюс все же есть пару таблиц где был создан «фальшивый» columnstore для отптимизации оконных функций и использования Window Aggregate, о чем на sqlmag также писал Бен Ган, в SQL 2017 Microsoft так и не дает использовать этот оператор без этого «трюка».
Все таки еще остался вопрос по Spill’ам. Т.к. оптимизатор используют Spoll чтобы, как сказано в вашей англ. язычной статье: «that one is used not to scan the first (build) input twice when we switch to a NL join. That is why we see a Worktable in the statistics IO output». В этом же примере видно что SQL эту таблицу не использовал, т.к. был использован Hash Join, он ее просто построил. Получается когда SQL к примеру сканирует input он строит сразу две таблиц, Hash и Worktable. Т.е. как я понимаю, он строит ее в любом случае, но использует лишь при NL Join. Если же был бы использован NL Join тогда бы было чтение из WorkTable. Отсюда и вопрос, ясно что при использование Hash Join могут быть Spill, но теперь получается что на диск при Spill может уйти не только Hash Table построенная для Hash Join, но и Worktable, которая строится в любом случае, и также может быть Spill этой таблицы при выборе NL Join?
Возможно я просто не так понял принцип работы этого оператора.
По поводу Spool, нет две таблицы не строится. Дальше в статье написано:
Т.е. это не Spool в классическом понимании.
Если вы вспомните планы в которых вы видели Spool, то в них есть заполнение Spool-а, т.е. он всегда принимает на вход какие-то данные, а не возникает из ниоткуда, потом в других ветках плана данные записанные в Spool могут быть прочитаны. Например, запрос: select count(*) over() from master..spt_values; — даст такой план. В верхней ветке плана, вы видите, как Spool наполняется из таблицы, в нижних, из него читается (хоть это в плане выглядит как отдельные операторы, у нижних операторов Spool есть свойство Primary Node ID ссылающееся на Node ID верхнего Spool-а).
В данном случае, Spool как-будто возникает из воздуха, мы не видим, момент его заполнения. Также у него нет свойства Primary Node ID. Но это нормально, ведь мы на недокументированной территории, MS не обязан корректно отображать все свойства. Этот Spool по сути буффер, который берет данные из Build части Hash Match-а. Я не писал этого в той статье подробно. Если посмотреть подробнее в дебаггере, то при заполнении хэш таблицы будет такой стэк вызовов (снизу-вверх):
Это запись в хэш таблицу, откуда потом будет читать наш, так называемый, «Spool».
Теперь чтение.
Если посмотреть что происходит после того как Adaptive Buf Reader читает строку, то будет видно такой стэк вызовов (снизу-вверх):
Это упрощенно, в реальности там очень много чего еще происходит. Worktable в понимании классического Spool вообще не строится (почему при этом выводится worktable в Statistics IO — сказать не могу).
Смысл в том, что копии данных нет, равно как и данные не читаются из таблицы повторно.
Раз такие вопросы возникают, допишу это в англоязычную статью, так что спасибо за вопрос!