




 PDF
PDF Недавно, просматривая план запроса, я обратил внимание, что в одной ветке плана таблицы соединяются при помощи Nested Loops Join (NL), хотя логичнее было бы видеть там Merge Join (SM). Я решил разобраться, почему так происходит и наткнулся на интересную особенность оптимизатора.
Недавно, просматривая план запроса, я обратил внимание, что в одной ветке плана таблицы соединяются при помощи Nested Loops Join (NL), хотя логичнее было бы видеть там Merge Join (SM). Я решил разобраться, почему так происходит и наткнулся на интересную особенность оптимизатора.
В качестве тестовых данных будем использовать простую суррогатную БД, ее вполне хватит для демонстрации эффекта.
[spoiler+DB opt]use master;
go
if db_id('opt') is not null drop database opt;
go
create database opt;
go
use opt;
go
create table t1(a int primary key, b int not null, c int check (c between 1 and 50));
create table t2(b int primary key, c int, d char(10));
create table t3(c int primary key);
go
insert into t1(a,b,c) select number, number%100+1, number%50+1 from master..spt_values where type = 'p' and number between 1 and 1000;
insert into t2(b,c) select number, number%100+1 from master..spt_values where type = 'p' and number between 1 and 1000;
insert into t3(c) select number from master..spt_values where type = 'p' and number between 1 and 1000;
go
alter table t1 add constraint fk_t2_b foreign key (b) references t2(b);
create index ix_b on t1(b asc) include (c);
go
[/spoiler]
Выбор типа соединения
Выполним два запроса и посмотрим их планы.
select * from t1 join t2 on t1.b = t2.b where t1.b <= 36 order by t1.b, t2.b select * from t1 join t2 on t1.b = t2.b where t1.b <= 37 order by t1.b, t2.b go
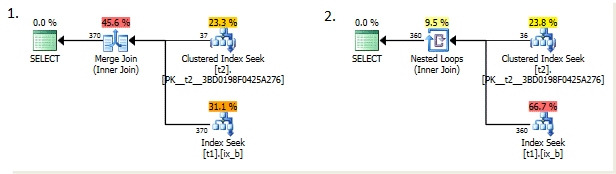
Выбирая тип соединения, да и вообще, выбирая какой оператор использовать, оптимизатор основывается на стоимости. Стоимость измеряется в некоторых условных единицах, которые сами по себе не имеют большого смысла, но используются при сравнении двух возможных вариантов – выбирается тот вариант, чья стоимость меньше, т.е. более дешевый вариант. Одной из самых важных величин влияющих на стоимость является число строк. В данном случае, начиная с определенного кол-ва строк, становится более выгодным использовать Nested Loops (NL) вместо Merge Join (SM). Поэтому неудивительно, что в запросе, приведенном ниже, который выбирает всего 10 строк, тоже используется соединение NL.
select * from t1 join t2 on t1.b = t2.b where t1.b = 37 order by t1.b, t2.b
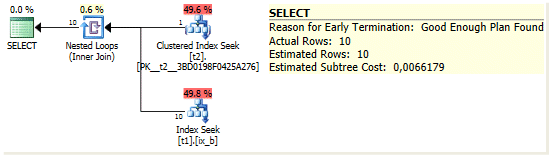
Теперь посмотрим, насколько дороже будет план, если при помощи подсказки заставить оптимизатор использовать Merge Join принудительно.
select * from t1 join t2 on t1.b = t2.b where t1.b = 37 order by t1.b, t2.b option(merge join) go

Сюрприз.
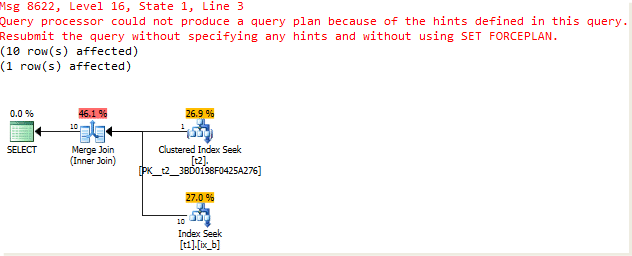
Оказывается, в такой ситуации оптимизатор не может построить план с Merge Join. Тот же самый результат будет, если добавить Hash Join.
select * from t1 join t2 on t1.b = t2.b where t1.b = 37 order by t1.b, t2.b option(merge join, hash join) go
Остается непонятным, почему оптимизатор в такой ситуации не может использовать ничего, кроме соединения NL.
Интересные эффекты
Ситуация становится более интересной, если попробовать написать запрос по-разному.
1.
/* 1. */ -- ERROR select * from t1 join t2 on t1.b = t2.b where t1.b = 1 option(recompile,merge join,hash join); go --OK select * from t1 join t2 on t1.b = t2.b where t1.b > 0 and t1.b < 2 option(recompile,merge join,hash join); go
2.
Такой же результат будет, если переписать запрос другим способом.
/* 2. */ -- ERROR select * from t1 join t2 on t1.b = t2.b where t1.b = 1 option(recompile,merge join,hash join); go --OK select * from t1 join t2 on t1.b+1 = t2.b+1 where t1.b = 1 option(recompile,merge join,hash join);
Сообщение о невозможности построить план в первом случае и план с SM соединением во втором.
3.
Еще один вариант.
/* 3. */ -- ERROR select * from t1 join t2 on t1.b = t2.b where t1.b in (1) option(recompile,merge join,hash join); go --OK select * from t1 join t2 on t1.b = t2.b where t1.b in (1,2) option(recompile,merge join,hash join); go
4.
И еще один.
/* 4. */ -- ERROR select * from t1 join t2 on t1.a = t2.b and t1.b = t2.c where t1.b = 1 and t1.a = 100 option(recompile,merge join,hash join); go --OK select * from t1 join t2 on t1.a = t2.b and t1.b = t2.c where t1.b = 1 option(recompile,merge join,hash join); go
5.
Такая же проблема в запросе с переменной и опцией рекомпиляции.
/* 5. */ -- ERROR declare @b int = 1; select * from t1 join t2 on t1.a = t2.b where t1.a = @b or @b is null option(recompile, merge join); go --OK declare @b int = null; select * from t1 join t2 on t1.a = t2.b where t1.a = @b or @b is null option(recompile, merge join); go
Можно придумать еще несколько примеров, но мне кажется этих уже достаточно. Более интересным будет разобраться в происходящем, поскольку за всеми этими примерами скрывается одна и та же манипуляция оптимизатора, приводящая к подобным результатам.
Причина
Оптимизатор начинает построение плана с построения дерева логических операторов, которое соответствует запросу. После этого, еще до того как начнется поиск вариантов, оптимизатор пытается всячески упростить это дерево. Одним из таких упрощений является попытка отфильтровать строки до выполнения операции соединения. Это логичный ход, поскольку, чем больше будет отфильтровано строк до выполнения соединения, тем меньше строк придется соединять и тем будет быстрее.
Посмотрим на запрос.
select * from t1 join t2 on t1.b = t2.b where t1.b = 1
Можно заметить, что в условии where фигурирует предикат с участием колонки t1.b. Проверяется t1.b=1. Та же колонка фигурирует и в предикате соединения t1.b = t2.b. Можно проследить транзитивную зависимость: если t1.b равно единице, а t2.b равно t1.b, следовательно, t2.b тоже равно единице. Значит, можно отфильтровать и по t2.b=1. Если мы отфильтровали обе таблицы по одному и тому же числу – t1.b = 1 и t2.b = 1 — зачем нам еще проверять в соединении то, что t1.b равно t2.b, это ведь всегда верно, т.к. они оба равны 1. Значит, можно исключить условие соединения, превратив inner join в некое подобие «cross join».
Именно это и делает оптимизатор.
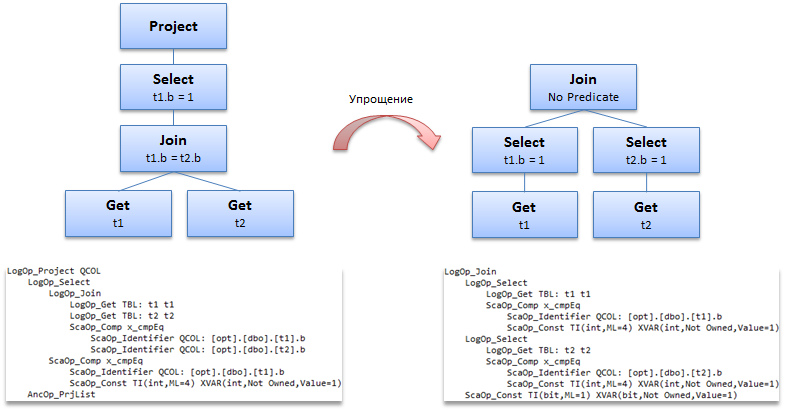
На данном этапе все в порядке, дерево упрощено и начинается основная оптимизация, т.е. поиск вариантов.
И вот тут появляется проблема. Мы ограничили возможные типы соединений SM и HS, и оба этих соединения требуют наличия хотя бы одного предиката равенства в условии соединения (equi predicate).
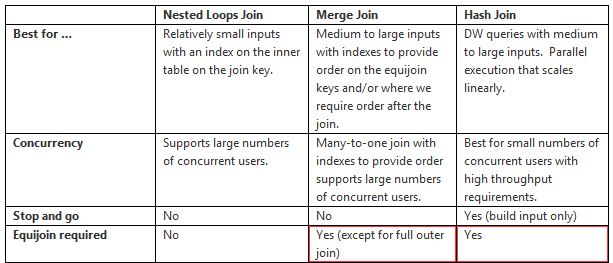
Craig Freedman — Summary of Join Properties
Однако оптимизатор исключил условие соединения на этапе упрощения, фактически, сам себя, ограничив только соединением NL – поскольку для этого типа соединения предиката равенства не требуется. И поскольку мы в свою очередь, ограничили оптимизатор хинтами типов соединений SM и HS, то получаем в результате сообщение о невозможности построить план, хотя, казалось бы, никаких предпосылок к этому нет.
Теперь два слова о приведенных выше примерах, точнее о тех частях (помечены как —OK в комментариях), которые работают и почему они работают.
1.
select * from t1 join t2 on t1.b = t2.b where t1.b > 0 and t1.b < 2 option(recompile,merge join,hash join);
В данном случае, нетрудно заметить, что в запросе попросту нет транзитивной зависимости t2.b=t1.b=1. Неравенства не дают оптимизатору выполнить упрощение, по этому, условие не исключается из соединения и остальные типы соединений остаются доступными.
Вопрос на засыпку, сможет ли оптимизатор построить план такого запроса? =)
select * from t1 join t2 on t1.b = t2.b where t1.b >= 1 and t1.b <= 1 option(recompile,merge join,hash join);
2.
select * from t1 join t2 on t1.b+1 = t2.b+1 where t1.b = 1 option(recompile,merge join,hash join); go
В примере два упрощение и исключение условия соединения невозможно, поскольку над полями соединения определены выражения t1.b+1 и t2.b+1. Сначала вычисляется фильтр (t1.b=1) и выражения, после этого выражения сравниваются в условии соединения, ошибки нет.
Интересно, что если отключить правило, предписывающее оптимизатору сделать фильтрацию при соединении SELonJN, то оптимизатор сначала попытается выполнить соединение (без всяких предикатов), а фильтрацию по выражениям поставит после соединения – благодаря этому, план снова не сможет быть найден. Можете попробовать сами.
select * from t1 join t2 on t1.b+1 = t2.b+1 where t1.b = 1 option(recompile,merge join,hash join, queryruleoff SELonJN); go
Также можете попробовать убрать хинты и посмотреть, какой дикий план получится без этой оптимизации c NL join. =) В том числе, будет видно, что соединение выполняется без предикатов.
3.
select * from t1 join t2 on t1.b = t2.b where t1.b in (1,2) option(recompile,merge join,hash join);
В третьем примере оптимизатор также предварительно фильтрует до соединения, но, поскольку теперь значения два, то исключать условие соединения нельзя, т.к. если после предварительно фильтрации значений будет два и больше, необходимо знать по какому условию соединять эти строки, т.е. условие t1.b = t2.b необходимо.
4.
select * from t1 join t2 on t1.a = t2.b and t1.b = t2.c where t1.b = 1 option(recompile,merge join,hash join); go
В этом примере, у нас есть дополнительный предикат t1.a = t2.b, именно он остается в условии соединения после исключения t1.b=t2.c. Это можно увидеть в свойствах оператора Merge в плане запроса.

5.
Наконец, последний, пятый пример.
declare @b int = null; select * from t1 join t2 on t1.a = t2.b where t1.a = @b or @b is null option(recompile, merge join); go
В нем решающую роль играет опция recompile и оптимизация parameter embedding optimization. Эта оптимизация стала доступна начиная с некоторого кумулятивного обновления серверов версий 2008, 2008R2 и далее. Благодаря тому, что в запросе используется опция перекомпиляции сервер строит план каждый раз когда выполняет запрос, не помещая его в кэш. Это значит, что в момент построения и момент выполнения совпадают, а значит сервер точно знает значения локальных переменных в момент построения плана. Поскольку сервер точно знает что в переменной @b содержится null, и условие @b is null выполняется всегда – он может полностью исключить условие where. И напротив, если в переменной значение 1, то мы приходим к варианту запроса из самого первого примера.
SQL Server 2012
Если вы запустите все приведенные запросы для которых план не может быть найден в 2012 сервере – то вы не получите ошибку. Мне это показалось странным, т.к. входные деревья и в 2008R2 и в 2012 сервере полностью совпадают. Т.е. 2012 сервер точно также упрощает и исключает условие соединения. Пришлось лезть глубже, чтобы найти причину.
Разница оказалась в том, как сервер строит альтернативы в процессе основной оптимизации и поиска вариантов. В 2012 сервере функциональность построения SM и HS расширили для подобных случаев, в частности добавив метод PexprConstructColumnEqualsColumnPredicate, который, как можно догадаться из названия, конструирует equi предикат для колонок соединения.
Вот как выглядит стек вызова функции построения SM в 2008R2 и 2012 серверах.
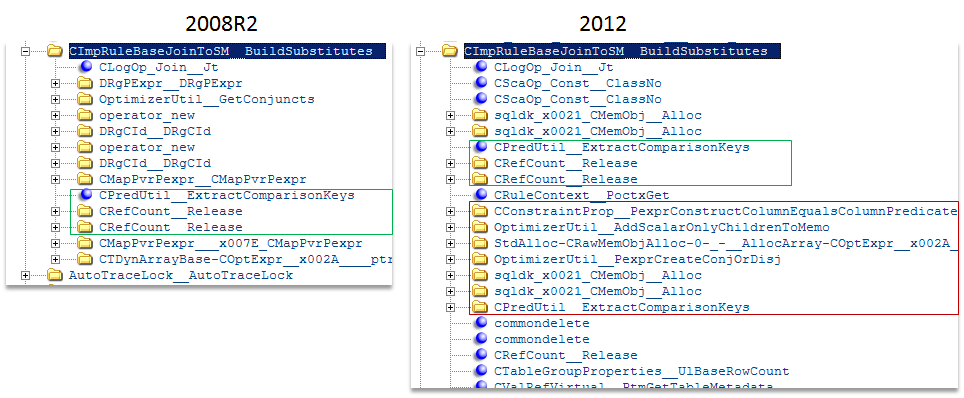
В 2008R2 после того как не удалось извлечь ключи для сравнения происходит выход из функции и переход к следующей. В 2012 сервере после этого же действия происходит вызов функции, которая принудительно генерирует предикат сравнения и повторный вызов функции генерации ключей сравнения.
Итог
Этот пример показывает, насколько интересные трансформации может делать оптимизатор и насколько они могут быть несовместимы с подсказками. Лишний аргумент пользоваться подсказками очень аккуратно и тестировать такие запросы при каждом изменении, включая значения возможных передаваемых параметров. Также пример показывает, что оптимизатор иногда способен выстрелить себе в ногу. =) Хотя в простых запросах, приведенных в качестве примеров, вопросов о целесообразности применения NL не возникает, но в сложных, часто параллельных планах, с множеством веток и более сложными зависимостями – будет полезно помнить об этом эффекте.
UPD. 2013-07-25.
А еще говорят, совпадений не бывает. Какова вероятность обратить внимание на эту особенность после стольких лет работы с сервером именно сейчас, и в то же время купить книжку аж 2006 года выпуска именно сейчас, где описан этот кейс =)
Купил вчера на Амазоне книгу SQL Server 2005 Practical Troubleshooting: The Database Engine by Ken Henderson
![]()
Эта книга давно была в моем wish list-е, но как-то я про нее подзабыл, а тут вспомнил. И вот выдержка из книги (я надеюсь это не будет нарушением авторских прав).

Автор данного раздела César Galindo-Legaria, один из архитекторов оптимизатора запросов, автор многочисленных академических статей и публикаций на данную тему.
Ну что же, зато теперь мы знаем, что ситуация изменилась, и в 2012 сервере хинты алгоритмов соединений в подобного рода запросах более не представляют опасности =)




