




 PDF
PDF
Когда-то, я уже писал заметки на тему факторов, ограничивающих процесс оптимизации, с целью сократить его время. Это timeout и good enough plan. Особенно подробно я расписывал концепцию таймаута, сегодня я хочу рассказать про «good enough plan». Я начну с одной любопытной, на мой взгляд, истории, которую слышал от одного из членов команды разработки оптимизатора на Платформе 2008. А недавно наткнулся на более подробную версию этой истории в Интернете, которая была даже снабжена фотографией. И хотя сами публикации довольно старые и история известна многим, я все же начну с нее, т.к. она релевантна теме заметки.
Cost
Когда-то давно, когда деревья были больше, трава зеленее, а компьютеры имели дисководы — велась разработка оптимизатора для версии SQL Server 7.0. Для того, чтобы сравнивать разные операторы плана между собой, и выбирать наиболее выгодные из них, нужен был некий механизм оценки стоимости каждого оператора, какие-то цифры. Разработчик, ответственный за это (источники говорят, что его звали Ник) взял за основу время выполнения операции на своей собственной машине. Таким образом, стоимость плана равная 1, означала что оптимизатор, оценивает время выполнения запроса на машине Ника в 1 секунду. Оттуда же пошли некоторые константы, например случайный доступ 320 операций в секунду породил константу 1/320 = 0.003125, которая и по сей день зашита внутри сервера и используется для оценки стоимости операции случайного доступа.
Сейчас, эти цифры не несут никакой смысловой нагрузки, как единицы измерения чего либо. Это просто некоторые коэффициенты, которые служат для сравнения операторов между собой. Можно думать о них, как о предполагаемых затратах ресурсов на выполнение плана. Ключевое слово — предполагаемых, т.к. они являются оценкой, которая выполняется в соответствии с моделью.
Оценка довольно часто находится в рассогласовании с реальностью, поэтому, очень часто люди удивляются, почему сравнивая два запроса один стоит 10%, второй 90%, но первый выполняется 90 секунд а второй 10. Тут же находят аргументы, что «правильно, на второй же больше ресурсов, значит выполнится быстрее» — это тоже в общем не совсем верно. Ведь может быть, что запрос который не может использовать индекс и имеет огромную стоимость — будет действительно долго выполняться, по сравнению с запросом который сможет использовать поиск по индексу, будет стоить дешевле и выполнится мгновенно. Ответ тут простой, не нужно полагаться на стоимость как на меру времени — это просто результат работы модели. Ошибка модели — ошибка в стоимости.
Простой пример, необновленная статитика по возрастающему ключу. Допустим, есть таблица в 10 000 000, в последний раз было загружено 10 000 строк, это менее 20%, статистика не обновилась, а никаких регламентных работ по ее обновлению нет. Запрос по условию — where id > 10 000 000. В гистограмме просто нет значений более чем 10 000 000, выдается оценка одна строка. При этом, как правило, запрос более сложный, обычно там есть соединения, а для небольшого числа строк выгоднее использовать Nested Loops, он и выбирается, и т.д. План оказывается не дорогим (ведь предполагаемое число строк равно единице). Запрос начинает выполняться — все очень медленно, хотя стоимость низкая! Но на самом-то деле, строк 10 000. Обновили статистику, построился другой план, с другими стратегиями доступа, типами соединения и может быть даже параллельный, который выполняется очень быстро! Хотя стоит намного дороже первого. Значит ли это, что сервер использовал больше ресурсов и по этому выполнил быстрее? Вовсе нет, это просто значит, что оптимизатор более «трезво» взглянул на вещи и построил более адекватный план, который оказался дороже, т.к. оценка предполагаемого числа строк была выше, но больше соответствовала действительности.
Но, вернемся к тому, что первоначально, стоимость 1 отражала оценку предполагаемого времени 1 секунда, на определенном оборудовании.

Машина Ника =)
Источники:
what “estimated subtree cost = 1” means ? or a great SQL server history story
Pruning
Оптимизация включает в себя много шагов, но применительно к заметке нас интересует сам процесс поиска плана. Оптимизатор не ищет наилучший план, он ищет достаточно хороший план быстро. Чтобы сократить время поиска оптимизатор старается сократить пространство исследуемых альтернатив отказываясь от исследования потенциально дорогих ветвей плана (pruning).
Для этого, в структуре Memo, в которой оптимизатор хранит альтернативные планы и которую использует для отслеживания наилучшего, на текущий момент, плана, для каждой из групп операторов устанавливаются границы. Из того что я видел, верхняя граница устанавливается как (лучшая стоимость)*1.1, т.е. 10% от стоимости. Возможно, есть и другие коэффициенты, но пока я видел только этот.
Если стоимость физического оператора превышает верхнюю границу группы — этот оператор (и все дочерние) — исключается из альтернатив как потенциально дорогие.
Good Enough Plan
Процесс поиска — итеративный процесс, по мере применения правил, наилучшая стоимость меняется, вместе с ней меняется и верхняя граница стоимости, после которой не имеет смысла рассматривать ветку плана. Атрибут Good Enough Plan добавляется тогда, когда стоимость корневой группы (т.е. по сути, потенциальная стоимость всего плана) стала меньше 1.
Эту логику можно объяснить просто, если верхняя граница, после которой все планы отбрасываются, становится меньше единицы, значит все последующие трансформации будут приводить к планам, стоимость которых тоже будет меньше единицы. Вспомним, что мы начали с того, что стоимость 1 — это одна секунда на машине Ника. Довольно похоже на человеческую логику, допустить, что если предполагается, что все последующие найденные планы будут выполняться менее чем за секунду, то зачем оптимизировать дальше, можно сказать, что план — достаточно хорош.
Сейчас корреляции со временем нет, более того, я даже не уверен, что причина Good Enough Plan действительно является сигналом «раннего завершения» поиска, а не просто добавляется если граница стоимости становится ниже 1. Например, в случае TimeOut-а, оптимизация действительно завершается рано, в случае Good Enough Plan — я пока не нашел этому подтверждения, что ж буду искать дальше.
Давайте посмотрим пример (использую бд opt)
use opt;
go
print('---------------------------------------------------')
-- fool optimizer to say there is 28006 rows and 10000 pages in the table
update statistics t1 with rowcount = 28006, pagecount = 10000
go
--good enough plan
select * from t1 where t1.b = 100
option(recompile
,querytraceon 3604
,querytraceon 8615 -- <-- Memo
,querytraceon 8609 -- <-- Optimization Stats
,querytraceon 8739 -- <-- Group Optimization Info
)
go
print('---------------------------------------------------')
go
-- fool optimizer to say there is 28007 rows and 10000 pages in the table
update statistics t1 with rowcount = 28007, pagecount = 10000
go
--full
select * from t1 where t1.b = 100
option(recompile
,querytraceon 3604
,querytraceon 8615 -- <-- Memo
,querytraceon 8609 -- <-- Optimization Stats
,querytraceon 8739 -- <-- Group Optimization Info
)
go
alter table t1 rebuild; -- <-- return stats back
В первом случае, мы обманули оптимизатор сказав что у нас в таблице 28006 строк (эти числа я подобрал эмпирически, чтобы приблизить границу стоимости к 1). Посмотрим на планы и на корневые группы в Memo:
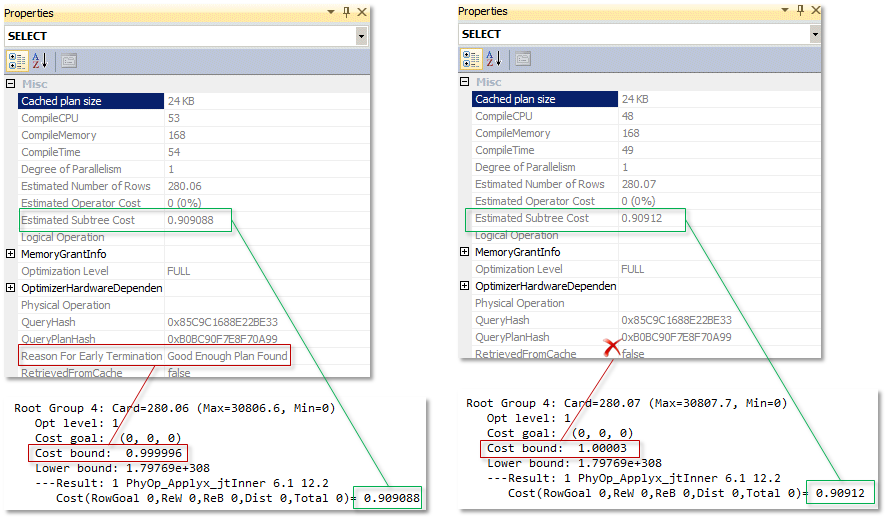
Слева результат для первого запроса, справа для второго. Стоимости оператора корневой группы совпадают со стоимостью плана (зеленые прямоугольники), а вот стоимость верхней границы, в первом случае чуть-чуть меньше единицы и мы видим в плане атрибут Good Enough Plan, а во втором чуть-чуть больше и такого атрибута в плане уже нет.
Disclaimer
Разумеется, это недокументировано и поведение может измениться. Более того, нельзя исключать возможности, что есть какие-то частные случаи когда это не так, но при помощи XQuery, я опросил около 800 000 Statements из разных планов на разных серверах, и нигде не увидел Good Enough Plan со стоимостью более 1.




