




 PDF
PDFПрослушивание параметров — это прием оптимизации, который позволяет использовать значения параметров модуля (например, хранимой процедуры или функции), во время первого вызова, для оценки предполагаемого числа строк при построении плана.
Прослушивание параметров в большинстве случаев полезная вещь, но эта техника плохо работает если значения параметров сильно отличаются по селективности. Например, в случае если для одного значения параметра выбирается 99% строк таблицы, а для второго 1% — серверу может быть выгодно использовать разные планы. Один план будет более эффективен для большего числа строк, второй для меньшего.
Однако, если работает прослушивание параметров, план будет построен для того значения, что было передано при первом вызове. Если для этого значения выбирается небольшое число строк, будет построен план выгодный для получения небольшого числа строк. Когда значение параметра изменится так, что процедура должна будет вернуть гораздо больше строк, план останется «старым», эффективным для небольшого числа строк. Давайте рассмотрим простой пример, который иллюстрирует проблему.
Описание Parameter Sniffing
В данном примере мы создаем тестовую таблицу в 1 миллион строк с кластерным и некластерным индексом. После чего, создаем процедуру, которая считает сумму некоторых значений для тех строк, у которых колонка b меньше переданного параметра. (Обратите внимание на новый синтаксис CREATE OR ALTER, доступный в SQL Server начиная с версии 2016 SP1)
use opt; go -- Создадим таблицу в 1 миллион строк drop table if exists t; with cte as (select top(1000000) rn = row_number() over(order by (select null)) from sys.all_columns c1,sys.all_columns c2) select a = rn, b = rn, c = rn into t from cte; -- Создадим кластерный и неклстерный индексы create clustered index cix on t(a); create index ix_b on t(b); go -- Создадим процедуру, считащую сумму в зависимости от параметра create or alter procedure p_sniff @b int as set nocount on; select sum(t.c) from dbo.t where t.b <= @b; go
Теперь, давайте запустим процедуру сначала для с параметром @b = 1, потом с параметром @b = 10000. Очевидно, чем больше значение параметра, тем больше строк придется прочитать серверу. Затем, пометим процедуру для повторной компиляции и повторим вызовы в обратном порядке.
-- 1. set statistics io, xml on; exec p_sniff 1; exec p_sniff 10000; set statistics io , xml off; go exec sp_recompile p_sniff; go -- 2. set statistics io, xml on; exec p_sniff 10000; exec p_sniff 1; set statistics io, xml off; go
Для небольшого числа строк, выгоднее использовать некластерный индекс, и, т.к. он не покрывающий (содержит не все поля, нужные запросу), обратиться за недостающими полями в кластерный индекс, т.е. сделать Key Lookup. Это происходит при первом вызове процедуры. Обратите внимание, на свойства Parameter List оператора SELECT, значения Parameter Compiled Value (значение для которого была скомпилирована процедура) и Parameter Runtime Value (значение с которым реально выполнялась процедура) совпадают.

Во второй раз, значение параметра 10 000 и требуется прочитать гораздо больше строк. Сервер может точно также выполнить поиск в некластерном и обратиться за недостающими значениями в кластерный индекс, но обращение в кластерный индекс – это операция случайного доступа и т.к. строк стало гораздо больше, появилось гораздо больше операций случайного доступа. В нормальной ситуации сервер сочтет это не выгодной стратегией, т.к. случайный доступ медленнее последовательного и просто выберет сканирование кластерного индекса. Однако, из-за прослушивания параметров план не перестраивается, а просто используется тот план, что был построен для значения 1.

Обратите внимание, что теперь значение параметра, для которого скомпилирована процедура, отличается от значения, с которым процедура выполнялась. Из-за такой невыгодной стратегии во втором случае мы можем наблюдать большое число логических чтений:
Table ‘t’. Scan count 1, logical reads 6, physical reads 0, …
Table ‘t’. Scan count 1, logical reads 30031, physical reads 0, …
Потом мы пометили процедуру для рекомпиляции и запустили вызовы в обратном порядке, теперь, при первом выполнении план будет построен для значения 10 000, а при втором будет использован он же.

Мы можем наблюдать, что теперь логические чтения совпадают, поскольку и в том и в другом случае объем прочитанных данных один и тот же – полное сканирование кластерного индекса cix.
Table ‘t’. Scan count 1, logical reads 4097, physical reads 0, …
Table ‘t’. Scan count 1, logical reads 4097, physical reads 0, …
Второй план более универсальный и будет всегда работать за одно и то же среднее время в независимости от значения параметра. Первый план будет хорошо работать, когда возвращается небольшое число строк, и очень медленно, когда возвращается большое число строк.
Прослушивание параметров довольно распространенная проблема, я не буду подробно описывать все нюансы, т.к. уже есть много статей на эту тему, например, статья Slow in the Application, Fast in SSMS и ее перевод на русский.
Есть много способов решения проблемы прослушивания параметров, перечислим некоторые из них: использование разных веток кода, использование динамического SQL, замена параметров локальными переменными, использование хинтов recompile, optimize for, использование флага трассировки 4136 и т.д.
Начиная с SQL Server 2016 SP1, мы можем также отключать прослушивание параметров при помощи хинта DISABLE_PARAMETER_SNIFFING.
Стоит также упомянуть настройку БД, если вы хотите выключить прослушивание параметров для всей базы (настройка также доступна для secondary):
ALTER DATABASE SCOPED CONFIGURATION SET PARAMETER_SNIFFING = OFF; GO ALTER DATABASE SCOPED CONFIGURATION FOR SECONDARY SET PARAMETER_SNIFFING = OFF; GO
Хинт DISABLE_PARAMETER_SNIFFING
Давайте посмотрим пример того, как работает хинт DISABLE_PARAMETER_SNIFFING, для демонстрации используем те же данные что и в первом примере.
-- Создадим процедуру, считащую сумму в зависимости от параметра
create or alter procedure p_sniff
@b int
as
set nocount on;
select sum(t.c) from dbo.t where t.b <= @b option(use hint ('DISABLE_PARAMETER_SNIFFING'));
go
-- 1.
set statistics io, xml on;
exec p_sniff 1;
exec p_sniff 10000;
set statistics io, xml off;
go
exec sp_recompile p_sniff;
go
-- 2.
set statistics io, xml on;
exec p_sniff 10000;
exec p_sniff 1;
set statistics io, xml off;
go
Во всех случаях используется одна и та же форма плана со сканированием кластерного индекса. При этом оптимизация выполняется так, как если бы значение параметра @b было неизвестно (оценка строк – догадка 30% строк в таблице – 300 000 от 1 000 000).

Также, обратите внимание, что свойство Parameter Compiled Value исчезло, т.к. компиляция идет для неизвестного значения. Кстати, здесь есть небольшое отличие, при использовании флага трассировки 4136 свойство Parameter Compiled Value остается и сохраняет значение, которое было передано при первом выполнении, однако, оно не используется при компиляции.
Отличие от OPTIMIZE FOR UNKNOWN
Может возникнуть вопрос, есть ли какое-то отличие хинта DISABLE_PARAMETER_SNIFFING от хинта OPTIMIZE FOR UNKNOWN. Существенное отличие в том, что при помощи хинта OPTIMIZE FOR UNKNOWN вы можете указать конкретный параметр, который нужно оптимизировать так, как если бы его значение было неизвестным. Например, OPTIMIZE FOR (@b UNKNOWN) и если в запросе участвуют другие параметры, то запрос будет оптимизироваться с параметром @b как неизвестным, но остальные будут прослушаны, тогда как хинт DISABLE_PARAMETER_SNIFFING отключит прослушивание всех параметров.
Второе отличие, менее очевидное, появляется если использовать эти хинты совместно с хинтом RECOMPILE. Рассмотрим пример:
create or alter procedure p_sniff
@b int
as
set nocount on;
select sum(t.c) from dbo.t where t.b <= @b option(recompile, optimize for unknown);
select sum(t.c) from dbo.t where t.b <= @b option(recompile, use hint ('DISABLE_PARAMETER_SNIFFING'));
go
exec p_sniff 1;
go
Несмотря на то, что в первом запросе мы используем RECOMPILE, запрос, тем не менее оптимизируется так, как если бы значение параметра не было известно в момент рекомпиляции. Во втором случае, несмотря на то, что прослушивание параметров отключено, сервер в момент рекомпиляции использует значение параметра и более того, применяет встраивание параметров (Parameter Embedding Optimization), т.е. заменяет параметры на их значения таким образом, как если бы в запросе изначально были константы.
Мы получаем разные планы:
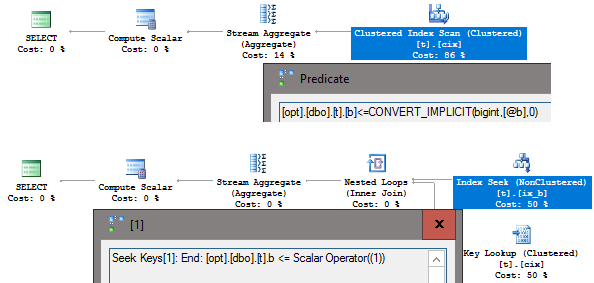
Трудно представить зачем сознательно использовать эти подсказки совместно с RECOMPILE. Но в реальности бывает всякое, например, невнимательность, небрежность или просто незнание, поэтому будет полезно знать о таком нюансе.
В следующий раз мы поговорим про хинт ASSUME_MIN_SELECTIVITY_FOR_FILTER_ESTIMATES.





Чоооорт, реально не понимаю, почему MS не запилят возможность кэшить разные планы для разных наборов параметров, например, с каким-нибудь таким синтаксисом (или любым другим, хоть как-нибудь):
option(optimize for @p IN (0-100, 101-1000, OTHER), @p2 IN (NULL OR », OTHER));
И компилить (и кэшить) соотвественно одинаковые планы для @p=1, @p2=NULL и @p=10, @p2=», но отличный для @p=100000, @p2=’filterText’. И включать соотвественно оптимизацию, как при RECOMPILE, только не с конкретными значениями, а с набором возможных значений (например, убирать AND (@p2 IS NULL or @p2 = » OR …)).
А то как-то не круто использовать один план на всех или перекомпилировать вообще всё всегда. Тем более, что разные наборы планов уже хранятся (только не для разных параметров, а для разных опций типа ANSI_NULL, ARITHABORT и т.д.)