




 PDF
PDFВ данной заметке мы разберемся что такое Row Goal для оптимизатора запроса, в каком случае он может навредить производительности, а также возможность его отключения для запроса при помощи подсказки DISABLE_OPTIMIZER_ROWGOAL.
Для иллюстрации проблемы, рассмотрим пример. Выполним два запроса, разница между ними только в том, что первый запрашивает все строки, второй ограничивает число строк одной, при помощи директивы TOP.
use AdventureworksDW2016CTP3; set nocount on; go set statistics time on; -- 1. Все строки select frs.UnitPrice, p.Class from dbo.DimDate dd join dbo.FactResellerSalesXL_PageCompressed frs on dd.DateKey = frs.OrderDateKey join dbo.DimProduct p on p.ProductKey = frs.ProductKey where dd.FullDateAlternateKey = '2014-12-31'; -- 2. Одна строка select top(1) frs.UnitPrice, p.Class from dbo.DimDate dd join dbo.FactResellerSalesXL_PageCompressed frs on dd.DateKey = frs.OrderDateKey join dbo.DimProduct p on p.ProductKey = frs.ProductKey where dd.FullDateAlternateKey = '2014-12-31'; set statistics time off;
Посмотрим на время выполнения:
SQL Server Execution Times:
CPU time = 2531 ms, elapsed time = 903 ms.
SQL Server Execution Times:
CPU time = 12797 ms, elapsed time = 13571 ms.
Из результатов видно, что первый запрос выполнился гораздо быстрее. Если мы посмотрим на планы, то увидим, что они отличаются.
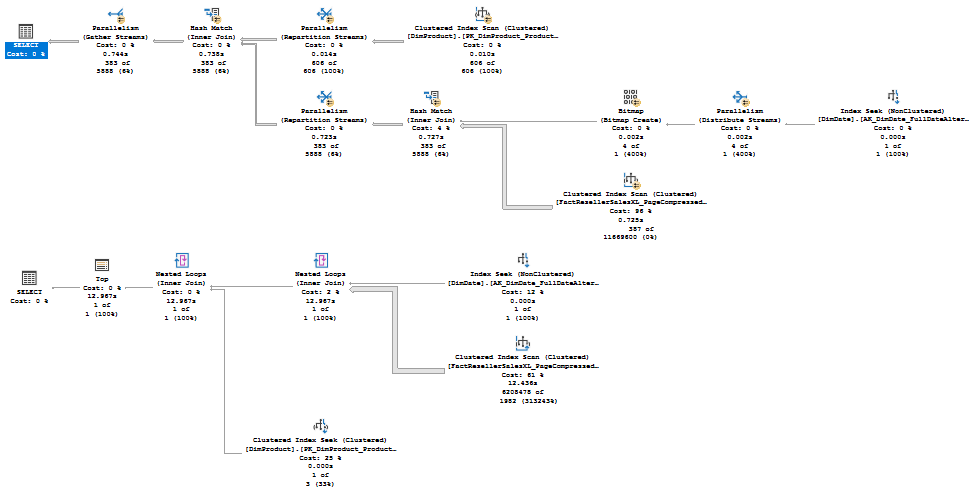
Причиной отличия является Row Goal (целевое количество строк)
Row Goal
Row Goal или целевое количество строк является механизмом оптимизатора, который, позволяет уменьшать оценку предполагаемого числа строк, когда заранее известно, какое количество строк необходимо получить.
В нашем случае, при помощи директивы TOP (1) мы указали оптимизатору, что хотим получить на выходе одну строку.
Далее в игру вступает модель оценки. Одним из факторов этой модели является предположение о равномерности данных, т.е. то, что все значения в таблице распределены равномерно.
Если мы хотим получить одну строку, то нужно найти одну строку в таблице DimDate, которая соответствует условию поиска по дате, а потом соединить со строками из таблицы FactResellerSalesXL_PageCompressed, но нет необходимости выполнять соединение по всем строкам, достаточно найти одну любую, которая соединится по условию dd.DateKey = frs.OrderDateKey (любую, т.к. мы не указали в предложении TOP инструкцию ORDER BY).
Таким образом оптимизатор рассчитывает, что ему не придется сканировать всю таблицу, придется просканировать только ее какую-то часть, пока не встретится эта самая одна строка, ведь оптимизатор полагает, что данные равномерны. Если данные равномерны, то сколько строк необходимо просмотреть, чтобы встретить искомое значение?
Для этого необходимо знать число уникальных значений. Например, если у нас есть ряд: 123321123213, с тремя уникальными значениями (1, 2 и 3), и они распределены равномерно, то сколько значений надо прочитать максимально, чтобы встретить, например, значение 3. Очевидно, что от одного значения до трех. Т.к. как три уникальных значения — это максимум, а данные равномерны, то прочитав три значения мы обаятельно найдем нужное.
В таблице такая же логика. Получить число уникальных строк мы можем из плотности столбца из объекта статистики, обратное к нему значение будет число уникальных значений. За это самое число мы обязательно найдем нужное.
dbcc show_statistics (FactResellerSalesXL_PageCompressed, _WA_Sys_00000002_114A936A) with no_infomsgs, density_vector;
Результат:
![]()
Количество уникальных значений:
select 1/0.0005045409
Результат:
1981.9998735484, если мы сравним с планом запроса, то пренебрегая погрешностями вычислений с плавающей точкой увидим, что вычисленный нами результат совпадает с оценкой Estimated Number Of Rows.
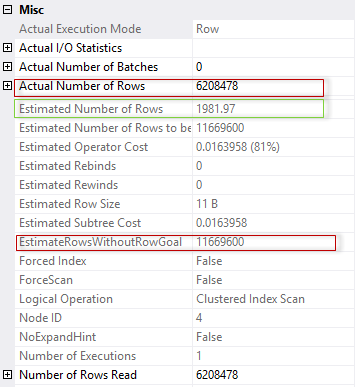
Исходя из такой оценки, небольшого числа предполагаемых строк, оптимизатор выбирает последовательный план с Nested Loops Join. Действительно, если бы было прочитана всего пара тысяч строк, это был бы эффективный подход.
Однако, реальность отличается от предположения. Можно заметить, что реальное число строк Actual Number Of Rows на порядок больше и равно 6208478 строкам.
Так происходит потому, что я специально выбрал дату, близкую к последним датам заказов, а поскольку даты заказов возрастают вместе с ключом кластерного индекса, нужные нам данные оказываются на последних страницах индекса.
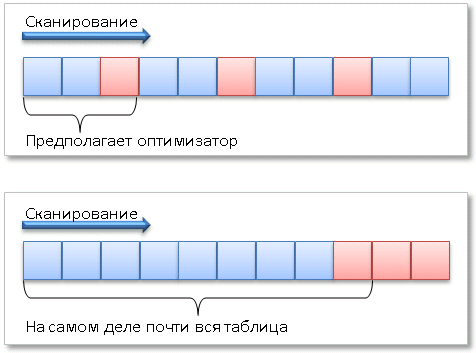
Таким образом, предположение модели о равномерности не соответствует реальности и сервер просматривает гораздо больше строк, чем рассчитывал.
В случае, если модель не работает как раз и могут помочь подсказки (хинты). Выполним запрос с подсказкой DISABLE_OPTIMIZER_ROWGOAL, которая отключает механизм Row Goal.
Примечание: В более ранних версиях сервера для этого можно использовать документированный флаг трассировки 4138.
set statistics time on;
-- 1. Все строки
select
frs.UnitPrice,
p.Class
from
dbo.DimDate dd
join dbo.FactResellerSalesXL_PageCompressed frs on dd.DateKey = frs.OrderDateKey
join dbo.DimProduct p on p.ProductKey = frs.ProductKey
where
dd.FullDateAlternateKey = '2014-12-31';
-- 2. Одна строка
select top(1)
frs.UnitPrice,
p.Class
from
dbo.DimDate dd
join dbo.FactResellerSalesXL_PageCompressed frs on dd.DateKey = frs.OrderDateKey
join dbo.DimProduct p on p.ProductKey = frs.ProductKey
where
dd.FullDateAlternateKey = '2014-12-31';
select top(1)
frs.UnitPrice,
p.Class
from
dbo.DimDate dd
join dbo.FactResellerSalesXL_PageCompressed frs on dd.DateKey = frs.OrderDateKey
join dbo.DimProduct p on p.ProductKey = frs.ProductKey
where
dd.FullDateAlternateKey = '2014-12-31'
option(use hint ('DISABLE_OPTIMIZER_ROWGOAL'));
set statistics time off;
Время выполнения:
SQL Server Execution Times:
CPU time = 2251 ms, elapsed time = 764 ms.
SQL Server Execution Times:
CPU time = 10515 ms, elapsed time = 11710 ms.
SQL Server Execution Times:
CPU time = 2266 ms, elapsed time = 2976 ms.
План запроса с отключенным Row Goal, к сожалению, не стал параллельным и не выполнился столь же быстро, как первый запрос, но уже гораздо лучше, чем второй, 2 секунды против 11.
План запроса без Row Goal:
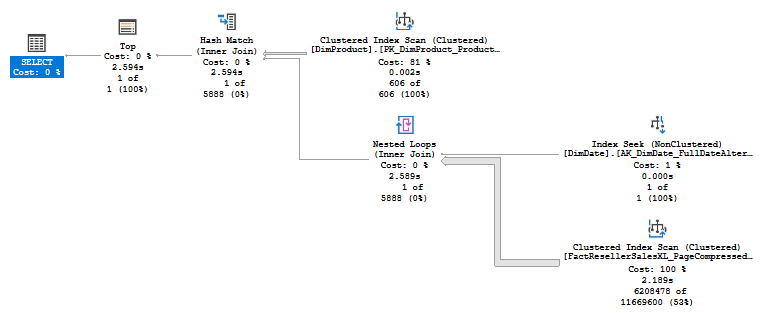
Можно увидеть, что изменилась форма плана и типа одного из соединений. К сожалению, план так и не стал параллельным, это связано с особенностями модели оценки стоимости. В качестве альтернативы, можно использовать следующую технику. Вместо значения в выражении TOP использовать переменную, после чего, использовать подсказку optimize for, где указать значение гораздо больше единицы, например max bigint.
Пример:
set statistics time on; declare @n bigint = 1; select top(@n) frs.UnitPrice, p.Class from dbo.DimDate dd join dbo.FactResellerSalesXL_PageCompressed frs on dd.DateKey = frs.OrderDateKey join dbo.DimProduct p on p.ProductKey = frs.ProductKey where dd.FullDateAlternateKey = '2014-12-31' option(optimize for (@n = 9223372036854775807)); set statistics time off;
В результате будет возвращена также одна строка, но план запроса будет похож на план самого первого запроса из этой статьи, он будет параллельным, а время выполнения соизмеримым. У меня оно составило:
SQL Server Execution Times:
CPU time = 2547 ms, elapsed time = 794 ms.
Механизм Row Goal включается не только тогда, когда есть явная инструкция TOP, но и в других случаях, когда сервер знает, что ему не нужно получать все строки.
Например, план такого запроса, тоже будет подвержен влиянию Row Goal.
if exists ( select 1 from dbo.DimDate dd join dbo.FactResellerSalesXL_PageCompressed frs on dd.DateKey = frs.OrderDateKey where dd.FullDateAlternateKey = '2014-12-31' ) select 1
Я не буду его здесь приводить, а оставлю вам в качестве эксперимента.
К сожалению, в подобных конструкциях подсказки уровня запроса (те, что задаются через инструкцию OPTION(…)), не поддерживаются. Если вам хотелось бы добавить эту поддержку, голосуйте за это на сайте MS: Query hints not allowed after or inside IF EXISTS().
Мы рассмотрели, как Row Goal может влиять на выполнение и план запроса, а также средства которыми можно отключать или изменять это поведение. На этом у меня все. Дополнительное описание принципов оценки и ограничения Row Goal можно найти в моей статье от 2012 года — RowGoal и неравномерное распределенных данных.




